A summary of the 2017 ISO/TC 307 Plenary in...
Blockchain

A neat report on the state of developer activity...



Blockchains Bitcoin Altcoins Litecoin Ethereum Cryptocurrencies Privacy_coins Mining Difficulty...

To debug a SubQuery project, the –inspect flag of...
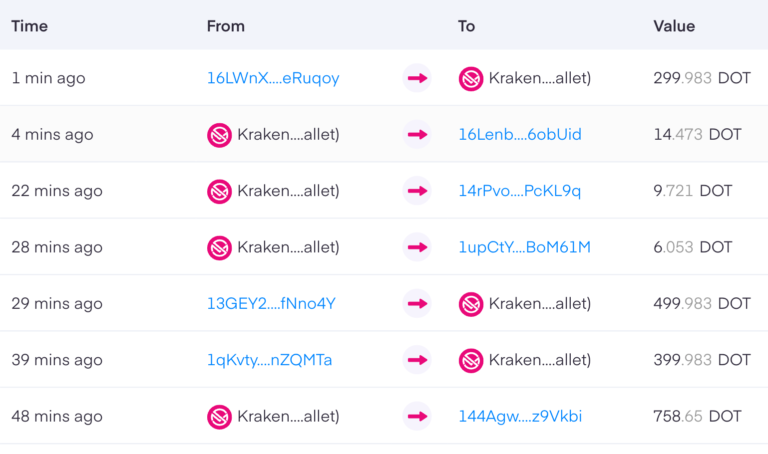
Introduction What we will do here is to write...

Here I catch up with Alex Sims, an Associate...

There are two URL resources available to check your...

To understand what the SubQuery dictionary is and how...
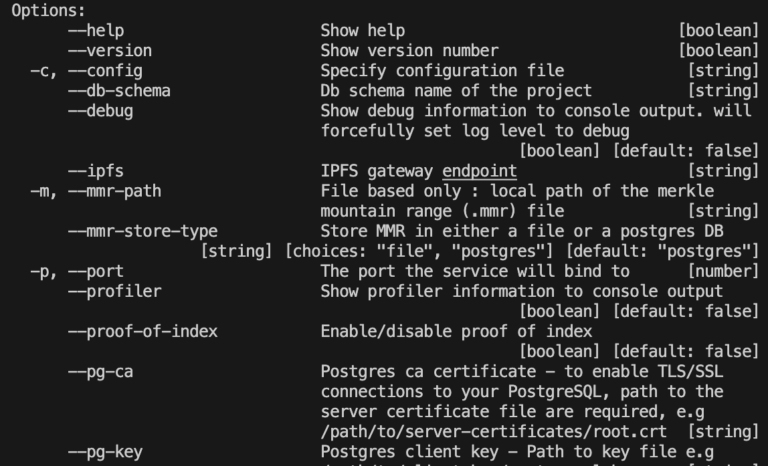
Sometimes the help within the command line can be...

At first, it may sound confusing but running an...
How to start at a different block height? TL;DR...
The SubQuery starter project is great way to get...

In SubQuery, you can log messages on 3 different...
SubQuery provides a very convenient service where you can...

Bryan Ventura is a senior lawyer at MinterEllisonRuddWatts. He...

Understanding a GraphQL schema is very confusing at first....
Introduction Once you have your project up and running,...