
Getting the SubQuery Fancy Greeter up and running only...
seandotau
blockchains, smart contracts, cryptocurrencies, software trainer & life long learner

Ollama is a free tool that allows you to...

The ISO/TC 307 plenary in Sydney concluded last week...
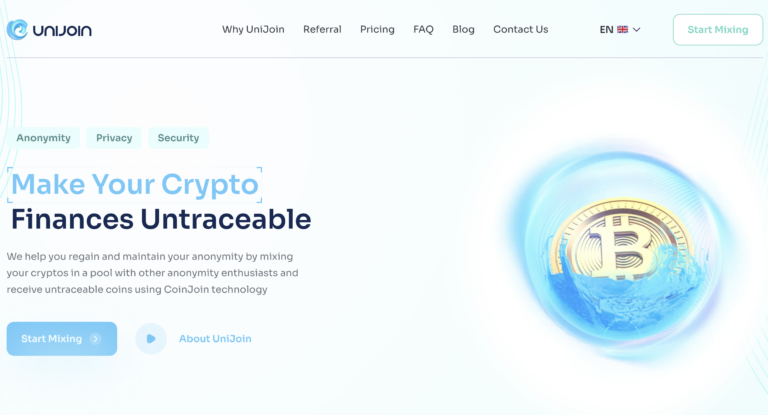
Current URL: https://unijoin.club/index.html Previous URL: https://unijoin.io/ Facebook: https://www.facebook.com/p/UniJoin-100083001897283 Reddit:...

URL: https://blindmixer.com/ Registered On: 2021-08-31 3 Oct 21: Bitcointalk:...

URL: https://yomix-1.com/ URL Registered On: 2024-02-23 13 Jan 24:...

Well worth a read. https://protos.com/tether-china Tether company structure: https://www.cftc.gov/media/6646/enftetherholdingsorder101521/download

Seized domains: https://samouraiwallet.com/ Alternative domains: https://samouraiwallet.io/ 3 Jun 19:...

Current URL: https://sinbad-mixer.io/ Previous URL: https://sinbad.io/ 14 Feb 23:...
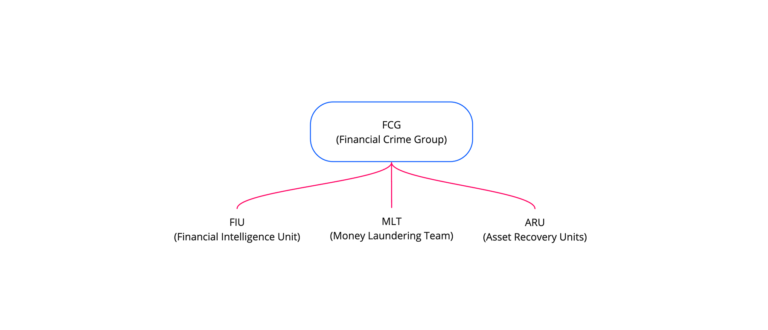
Within NZ Police, there is a Financial Crime Group...


A neat report on the state of developer activity...

If you have come across this error then you’ll...
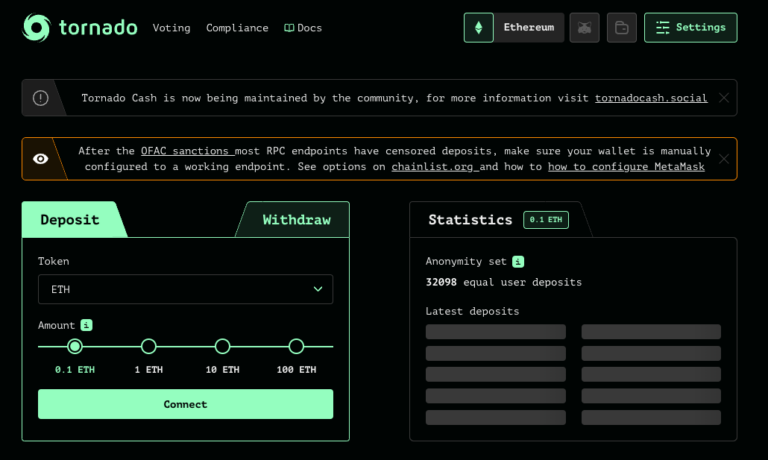
Original URL: https://tornado.cash New URL: https://tornado.ws/ 8 Aug 22:...

A neat video on the basics of verifying a...

Note: In version 14.5.1 of Bitpay’s crypto wallet, screenshots...