Introduction
Once you have your project up and running, the next task is to write queries for the data you want to retrieve. Back in the good old days, queries would conjure up the nostalgic SQL SELECT * FROM some_table_name. Nowadays things have changed somewhat.
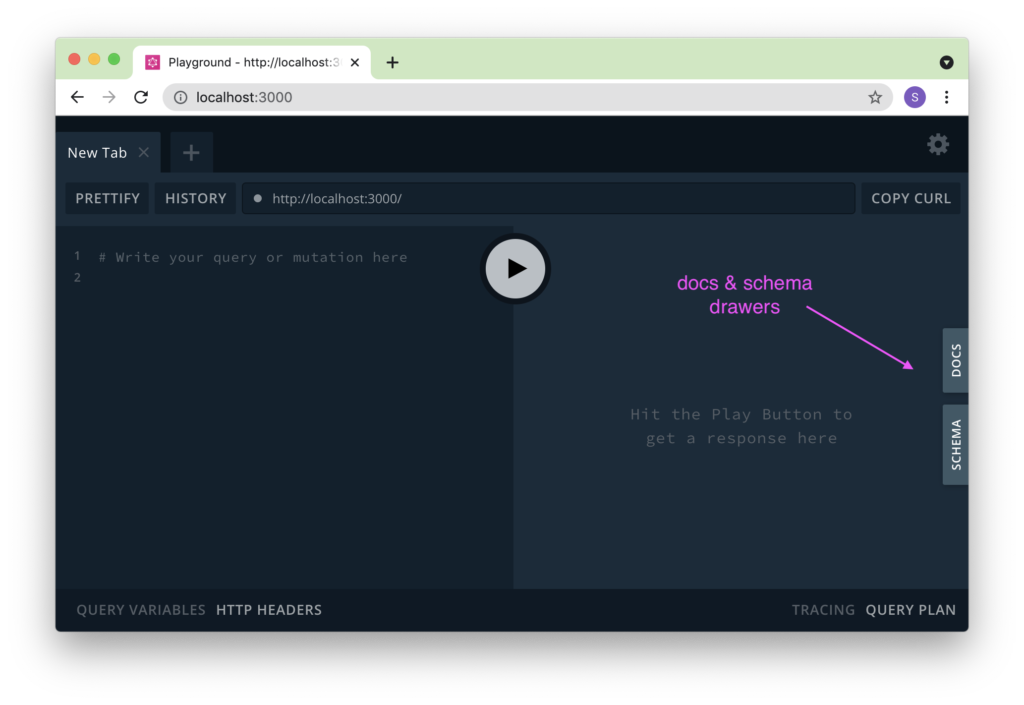
In your playground, ie localhost:3000 if you are running your project in a docker container, you will see two tabs on the right hand side labelled DOCS and SCHEMA. These drawers shoot out when you click on them and they are your bible in understanding what information is available to be queried. It can be daunting to first timers but we’ll step through some concrete examples to understand what this all means.
The block timestamp project
Before we examine the docs and the schema of this project, if you want to follow along, you’ll have to get the project up and running with a few simple commands.
git clone https://github.com/subquery/subql-examples/tree/main/block-timestamp
cd block-timestamp
yarn install
yarn codegen
yarn build
yarn start:dockerThen navigate to localhost:3000 and you should see the screenshot show above. Expanding each of these tabs will present you with the keywords that you can use to query your node for data.
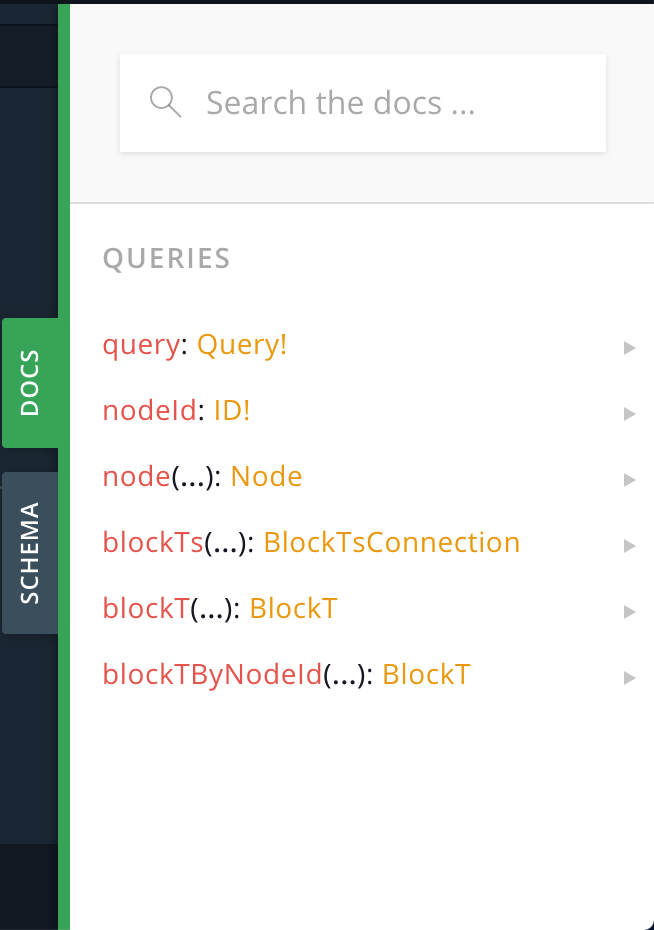
What you can see here is that there are 6 queries you can execute. query, nodeID, node, blockTs, blockT, blockTByNodeId. You are also told the “type” these queries are. eg the blockTs query is of “type” BlockTsConnection. Less obvious are query is of type query, node is of type Node, blockT is of type BlockT etc etc.
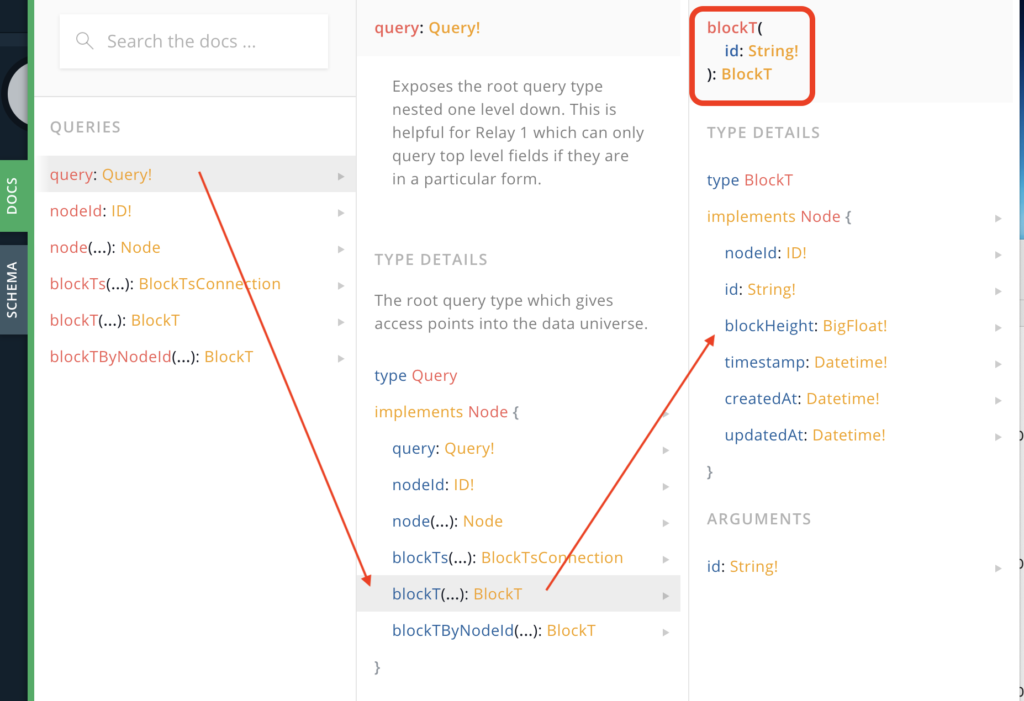
Still, this doesn’t help much. What will help are 2 pieces of information. Firstly, query is the root node and your “entry” point. You can see this when you click on the query
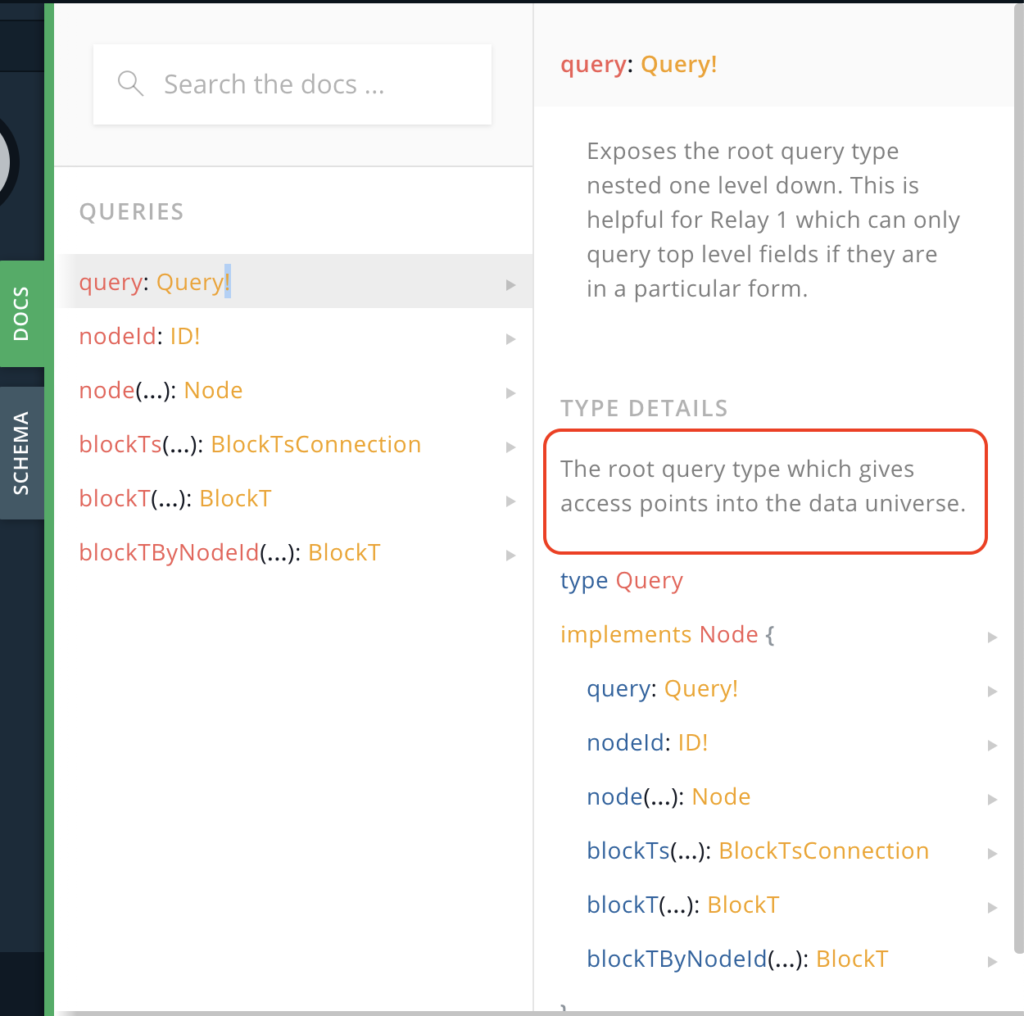
Secondly, you’ll want to explore the other queries to see what information you can retrieve. Take for example blockT. You can query for id, blockHeight, timestamp, etc. This looks interesting so let’s learn how to query for a simple blockHeight.
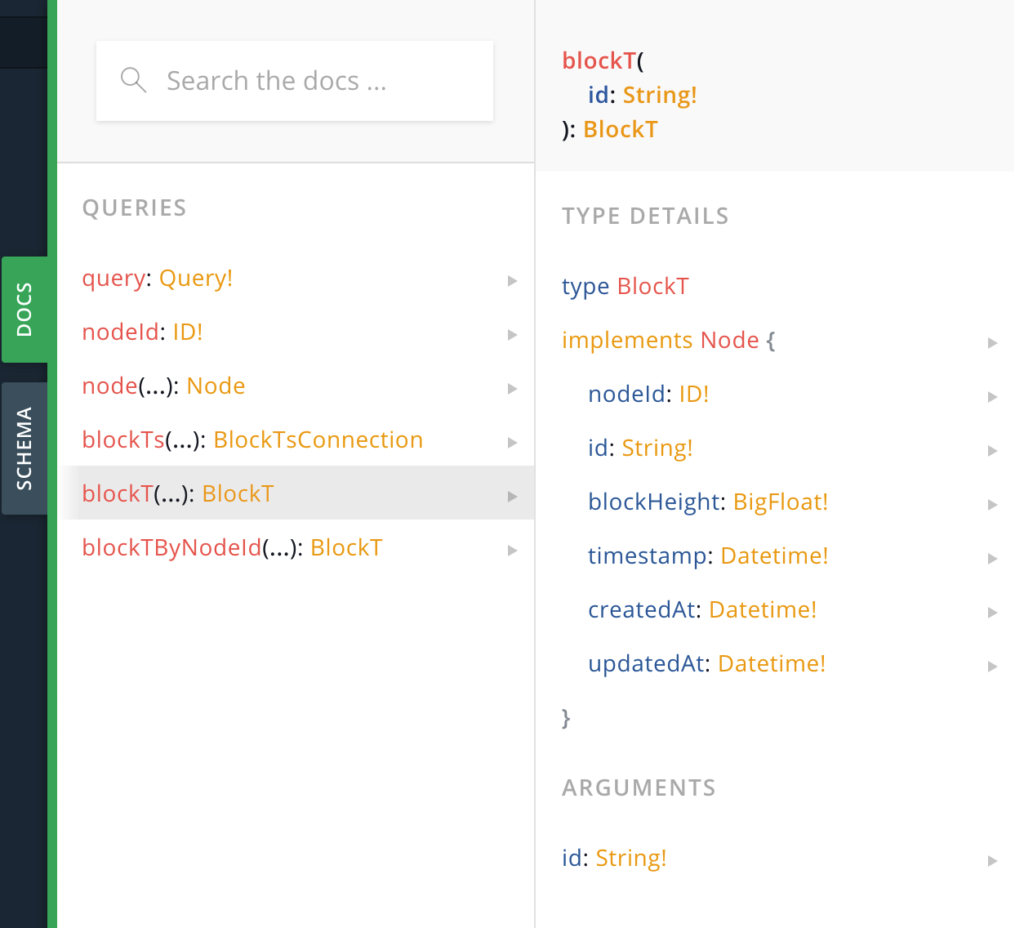
Querying for blockHeight with blockT
The first thing to write in your query panel is open bracket and then the keyword “query”. You’ll notice autocomplete appear. Autocomplete will be your new best friend because it is super duper useful.
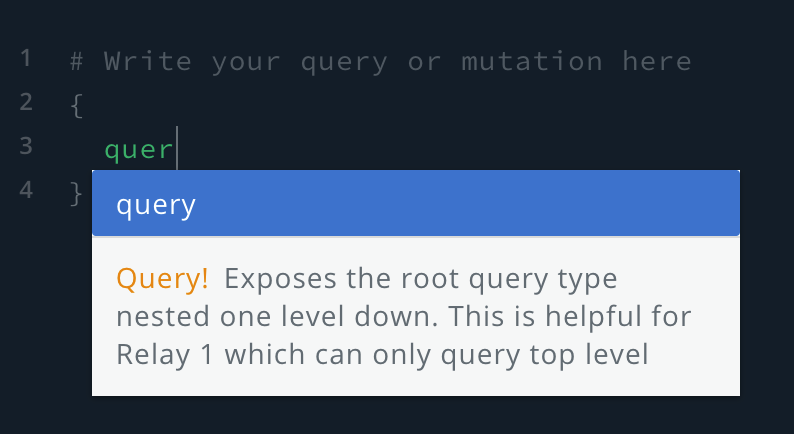
If you click run at this point, you’ll encounter an error.
Field \"query\" of type \"Query!\" must have a selection of subfields. Did you mean \"query { ... }\"?"This is because the query requires subfields.

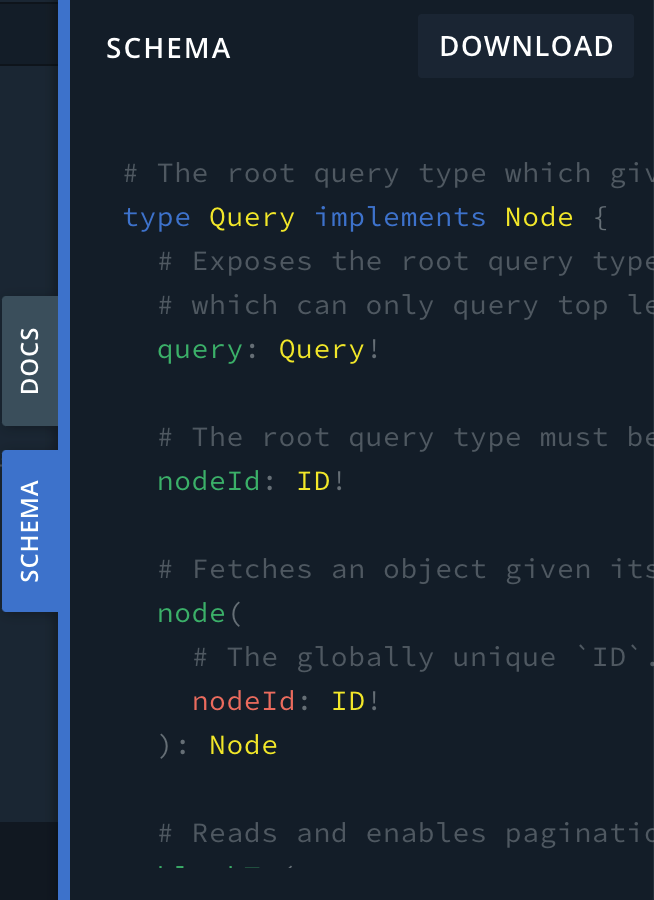
Clicking on the query link, you can see the subfields that it supports. This means that when you run a query, you have to tell the graphql engine what you want to query on. In our case, we want to query blockT because it contains the blockHeight that we want.
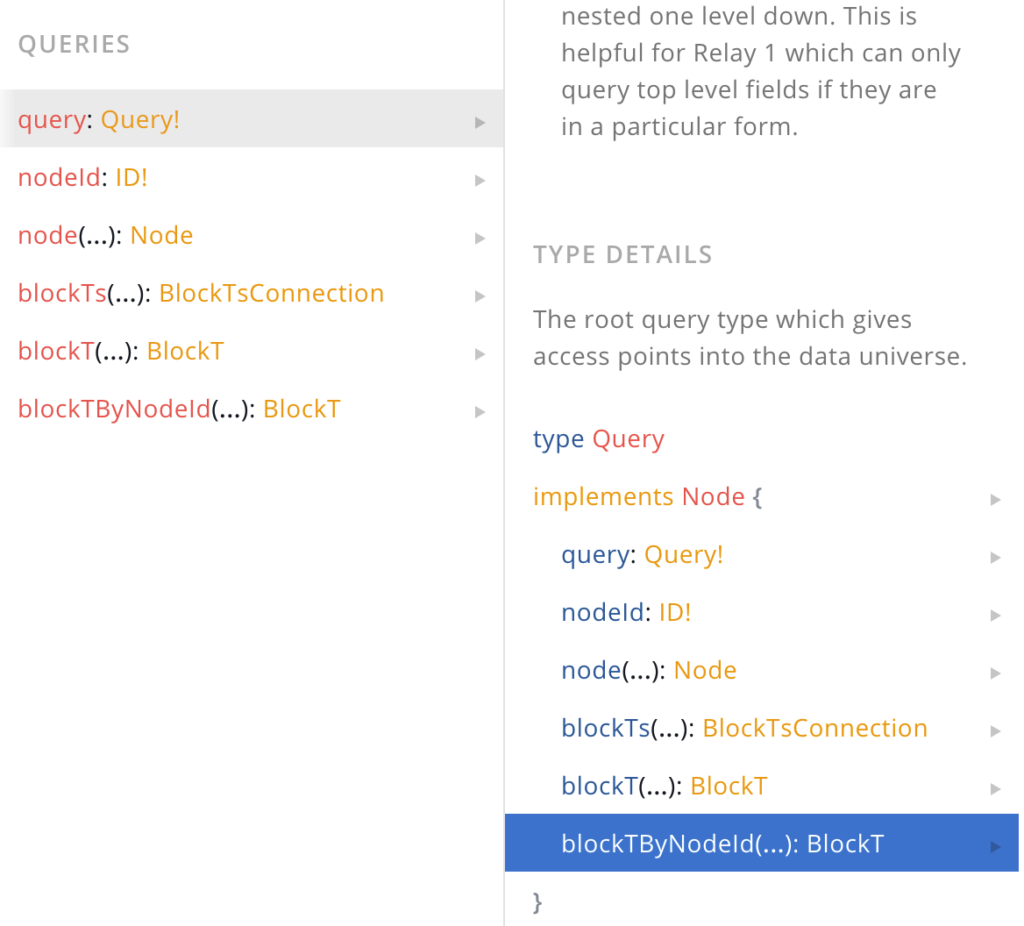
As soon as we start typing “bl”, you can see the autocomplete confirm that blockT is a valid subfield.
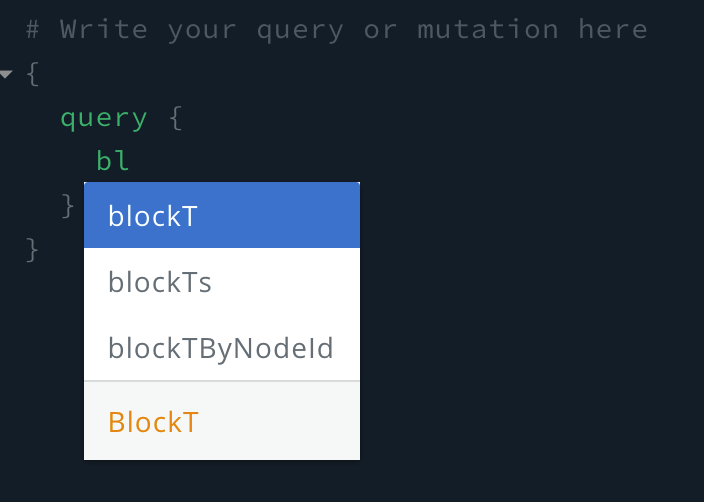
Again, if you click play, you’ll get the same error because blockT requires subfields. BlockT has the blockHeight subfield so let’s try that.
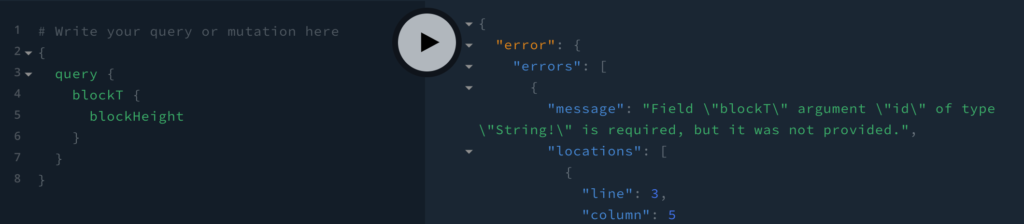
What you’ll find is that you get another error:
Field \"blockT\" argument \"id\" of type \"String!\" is required, but it was not provided.This is because blockT actually takes a mandatory argument called id that is of type String. The “!” means that it is a mandatory field. Therefore, the blockT query allows us to get the blockHeight for a specific id. So this is no use to use. Back to the drawing board.
Querying for blockHeight with blockTs
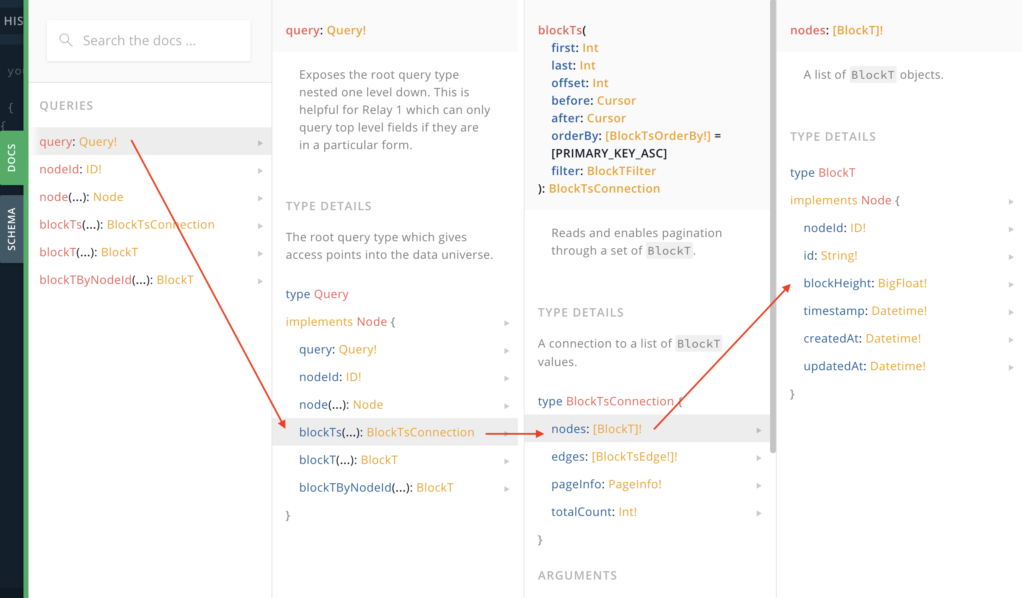
Exploring the documentation further, we can see that query > blockTs > nodes > blockHeight is a valid “pathway” so to speak. The trick here is that the query does not require an argument.
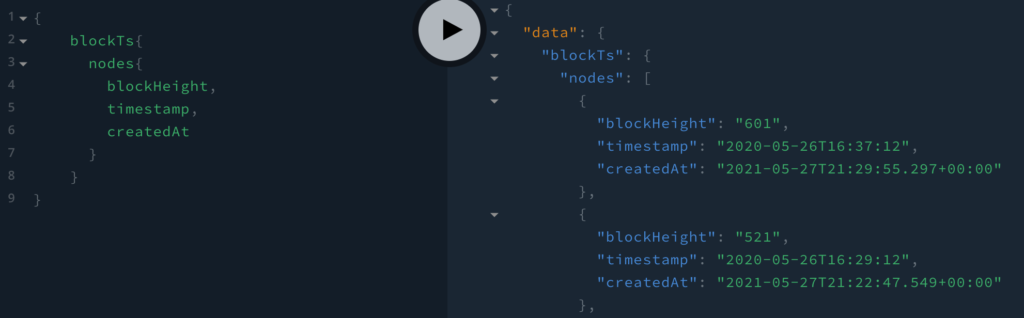
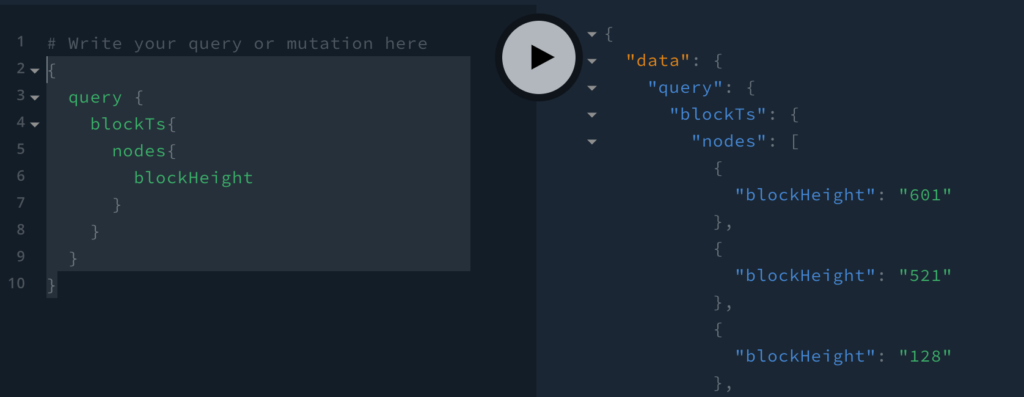
{
query {
blockTs{
nodes{
blockHeight
}
}
}
}Running this query produces the desired outcome.
Removing the query keyword
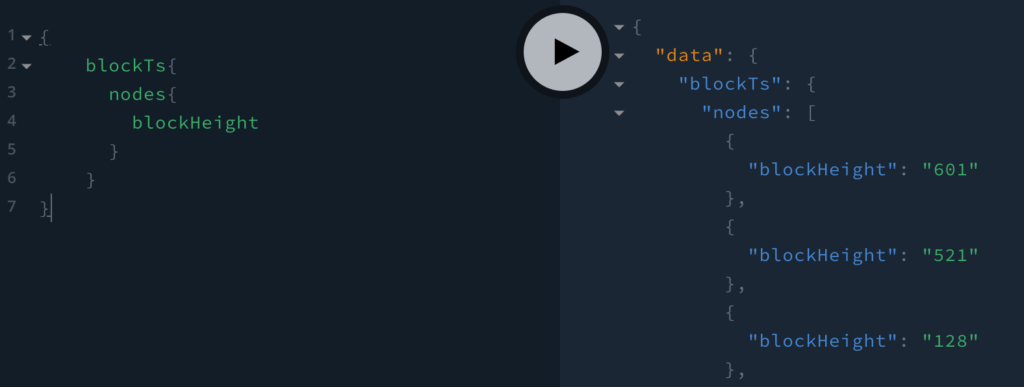
We can actually remove the “query” keyword to simplify the query and it will still work.
{
blockTs{
nodes{
blockHeight
}
}
}
Extending the query
We can now extend the query with other fields such as blockHeight, timestamp and createdAt.